本文共 2971 字,大约阅读时间需要 9 分钟。
本节书摘来自异步社区《数据科学:R语言实战》一书中的第1章,第1.2节,作者 【美】Dan Toomey(丹·图米),更多章节内容可以访问云栖社区“异步社区”公众号查看
1.2 异常检测
我们可以使用R编程来检测数据集中的异常。异常检测可用于入侵检测、欺诈检测、系统健康状态等不同领域。在R编程中,这些被称为异常值。R编程允许用多种方法对异常值进行检测:
- 统计测试;
- 基于深度的方法;
- 基于偏差的方法;
- 基于距离的方法;
- 基于密度的方法;
- 高维方法。
1.2.1 显示异常值
R编程存在可以显示异常值的函数:identify (in boxplot)。
boxplot函数生成了一个盒须图(请看下图)。boxplot函数有若干图形选项,比如此示例,我们无需进行任何设置。
identify函数是便于标记散点图中点的方法。在R编程中,箱线图是散点图的一种。
1.示例1
在此示例中,我们需要生成100个随机数,然后将盒中的点绘制成图。然后,我们用第一个异常值的标识符来对其进行标记:
> y <- rnorm(100)> boxplot(y)> identify(rep(1, length(y)), y, labels = seq_along(y))
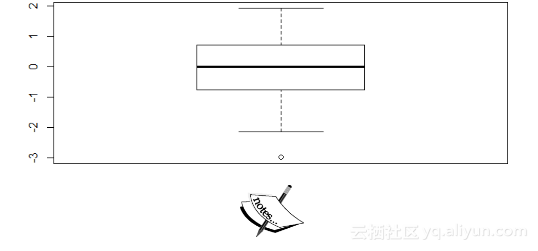
2.示例2
boxplot函数同样也会自动计算数据集的异常值。首先,我们会生成100个随机数(注意:此数据是随机生成的,所以结果可能不同):
> x <- rnorm(100)
可通过使用下列代码查看摘要信息:
> summary(x) Min. 1st Qu. Median Mean 3rd Qu. Max.-2.12000 -0.74790 -0.20060 -0.01711 0.49930 2.43200
现在,我们可以通过使用下列代码显示异常值:
> boxplot.stats(x)$out[1] 2.420850 2.432033
下列代码会用图表表示数据集,并且突出显示异常值:
> boxplot(x)..\16-0708 图\0860OS_01_11.png
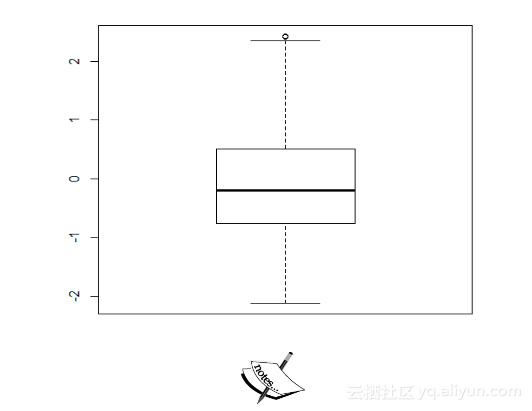
注意图中接近异常值的0。
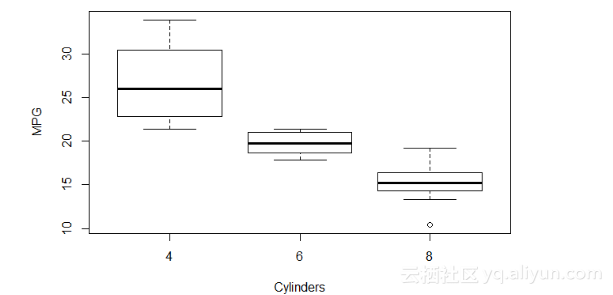
我们可以通过使用汽车的内置数据生成含有更常见数据的箱线图,这些数据与异常值存在相同的问题,如下所示:boxplot(mpg~cyl,data=mtcars, xlab="Cylinders", ylab="MPG")
3.另一个有关异常检测的示例
当有两个维度时,我们同样也可以使用箱线图的异常值检测。注意:我们通过使用x和y中异常值的并集而非交集解决问题。此示例就是要显示这样的点。代码如下所示:> x <- rnorm(1000)> y <- rnorm(1000)> f <- data.frame(x,y)> a <- boxplot.stats(x)$out> b <- boxplot.stats(y)$out> list <- union(a,b)> plot(f)> px <- f[f$x %in% a,]> py <- f[f$y %in% b,]> p <- rbind(px,py)> par(new=TRUE)> plot(p$x, p$y,cex=2,col=2)C:\Users\LL\Desktop\43590\image13.png
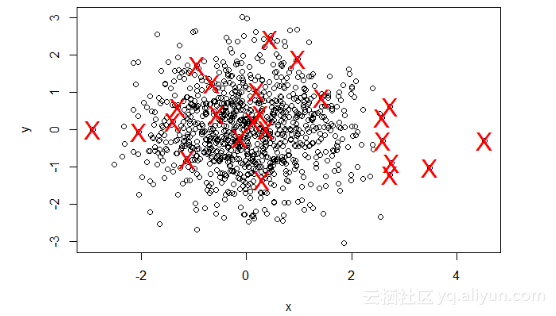
虽然R确实按照我们的要求去做了,但是此图看起来不对。我们完全是在编造数据,在真正的use case中,需要利用专业知识以便确定这些异常值是否正确。
1.2.2 计算异常
考虑到构成异常的多样性,R编程带有可以让您完全控制异常的机制:编写能够用于做决策的函数。
1.用法
我们可使用name函数创建异常,如下所示:name <- function(parameters,…) { # determine what constitutes an anomaly return(df)} 这里,参数是我们需要在函数中使用的数值。假设我们将函数返回为数据框。利用此函数可以完成任何工作。
2.示例1
我们会在此示例中使用iris数据,如下所示:> data <- read.csv("http://archive.ics.uci.edu/ml/machine-learningdatabases/iris/iris.data") 如果我们决定当萼片低于4.5或高于7.5时存在异常,就使用下列函数:
> outliers <- function(data, low, high) {> outs <- subset(data, data$X5.1 < low | data$X5.1 > high)> return(outs)>} 然后,我们会得出下列输出数据:
> outliers(data, 4.5, 7.5) X5.1 X3.5 X1.4 X0.2 Iris.setosa8 4.4 2.9 1.4 0.2 Iris-setosa13 4.3 3.0 1.1 0.1 Iris-setosa38 4.4 3.0 1.3 0.2 Iris-setosa42 4.4 3.2 1.3 0.2 Iris-setosa105 7.6 3.0 6.6 2.1 Iris-virginica117 7.7 3.8 6.7 2.2 Iris-virginica118 7.7 2.6 6.9 2.3 Iris-virginica122 7.7 2.8 6.7 2.0 Iris-virginica131 7.9 3.8 6.4 2.0 Iris-virginica135 7.7 3.0 6.1 2.3 Iris-virginica
为了获得预期的结果,可以通过向函数传送不同的参数值灵活地对准则进行轻微调整。
3.示例2
另一个受欢迎的功能包是DMwR。它包括同样可以用于定位异常值的lofactor函数。通过使用以下指令可对DMwR功能包进行安装:> install.packages("DMwR")> library(DMwR) 我们需要从数据上移除“种类”列,原因在于其是根据数据进行分类的。可通过使用以下指令完成移除:
> nospecies <- data[,1:4]
现在,我们确定框中的异常值:
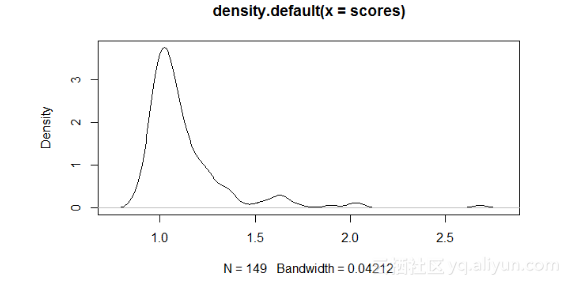
> scores <- lofactor(nospecies, k=3)
然后,我们查看异常值的分布:
> plot(density(scores))
转载地址:http://dosza.baihongyu.com/